A shopper types "red dress" into your search bar and gets nine results. You have forty-one red dresses in stock. The other thirty-two are tagged "crimson," "burgundy," "ruby," "wine," and one a vendor uploaded as "RD-447 / cherry-tone / FINAL." They never show up. The shopper assumes you don't carry what they want and leaves.
That's not a search problem. It's a data problem wearing a search problem's clothes. And it's the same reason a customer buys a camera lens that doesn't fit their mount, orders a 110V appliance for a 220V country, or returns a "water-resistant" watch after wearing it in the pool. Your product pages hold the answer somewhere. They just don't hold it in a form anything can reason about.
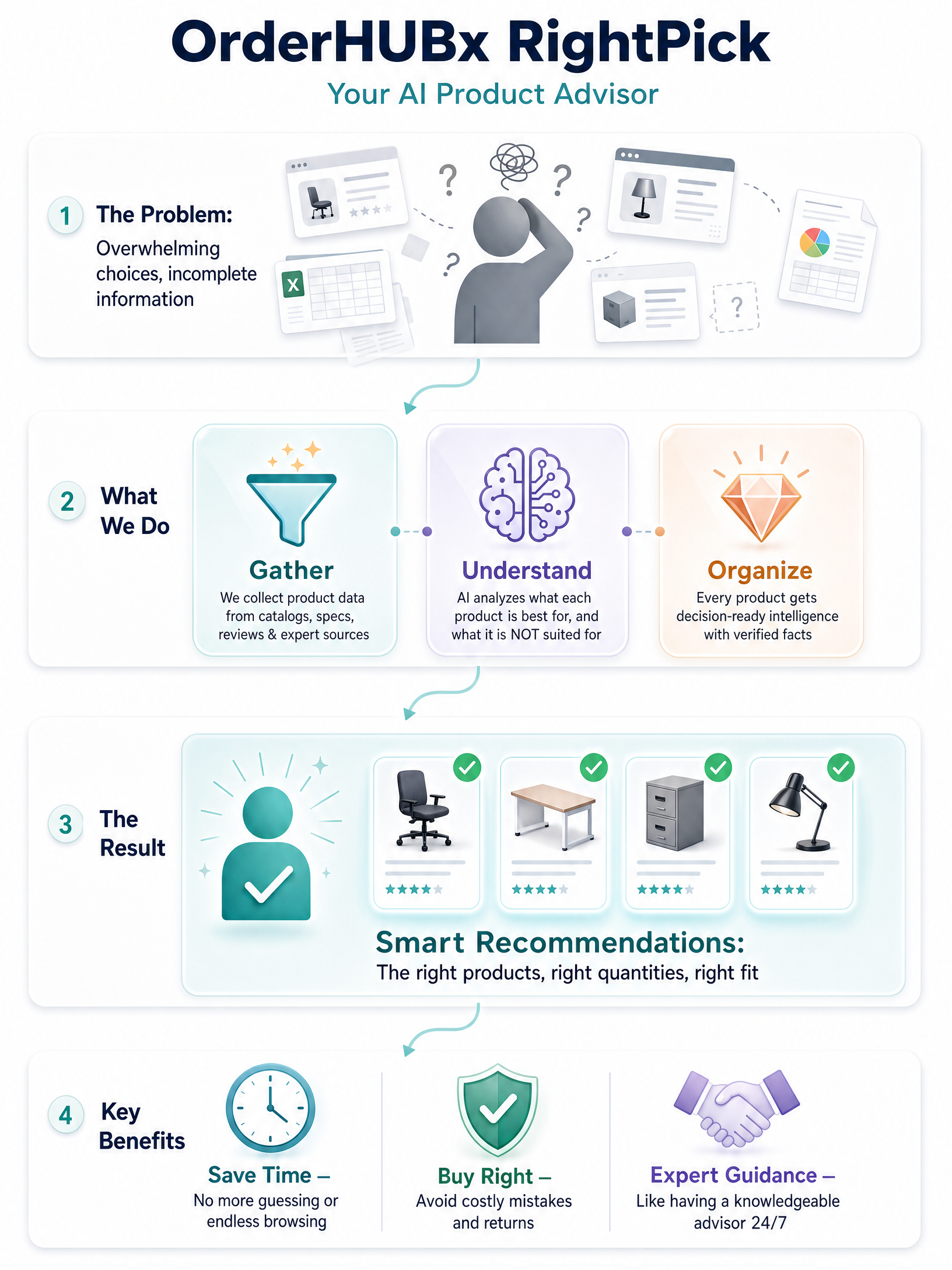{kind=link}
How OrderHUB x RightPick turns scattered catalog data into decision-ready product intelligence.
Your Catalog Is Full of Text, Empty of Meaning
Most catalogs were built to render a page, not to answer a question. A product has a title, a marketing blurb, maybe a bullet list, a price, and a photo. To a human reading one item at a time, that's enough. To a system trying to compare forty items or recommend a companion product, it's almost nothing.
Here's why. "Durable cotton blend tee, great for summer" reads fine. But your filters don't know its material is a cotton blend, that it's a summer-weight item, or that "durable" is a claim and not a measurement. Three vendors will write the same voltage as "110v," "110 volts," and "110 V" — and a filter treats those as three different things, or ignores all of them. The blurb that says a lens "fits most standard mounts" is worse than useless: it sounds reassuring and tells the buyer nothing about whether it fits _their_ body.
This is the gap a product intelligence platform exists to close. Not by writing better marketing copy, but by turning the copy you already have into structured facts a machine can sort, filter, compare, and reason over. A shallow product page becomes a set of decision-ready attributes. That shift is the whole game.
Enrichment: Turning Prose Into Facts
The first job is ecommerce product data enrichment — pulling the meaning out of the mess. Models read your titles, descriptions, bullet points, spec sheets, supplier feeds, and even the product photos, and they extract attributes you can actually act on. Material, color family, dimensions, weight, voltage, capacity, fit, use case. The things a shopper would ask a knowledgeable salesperson if one were standing there.
It does four things, roughly in this order. It extracts attributes that were buried in prose. It standardizes them so "crimson," "ruby," and "wine" all roll up to a red color family and "110v" and "110 volts" become one value. It adds compatibility — which lens fits which body, which battery powers which device, which refill matches which dispenser. And it adds context, the part humans actually use to decide: "water-resistant" is honest, but "fine for rain and a splash, not for swimming" is what stops the return.
| What enrichment does | What's on the page now | What the system gets |
|---|---|---|
| Extract attributes | "Durable cotton blend tee, great for summer." | Material: cotton blend · Season: summer · Weight: light |
| Standardize values | "110v", "110 volts", "110 V" | Voltage: 110V (single canonical value) |
| Add compatibility | "Fits most standard mounts." | Fits Mount A, Mount B; not Mount C |
| Add context | "Water-resistant." | Fine for rain and splashes; not for submersion |
None of this is glamorous work. It's the digital version of a stock clerk who has handled every item and can tell you, without checking, that the blue one runs small and the cheaper charger won't fast-charge your phone. Enrichment bottles that knowledge and applies it to every SKU, including the four hundred you uploaded in a hurry two years ago and never touched again.
Why a Knowledge Graph, Not Just More Columns
You could stop at enrichment, dump everything into a spreadsheet with a hundred columns, and call it a day. Plenty of teams do. The trouble is that a flat table can store facts but can't connect them. It knows a lens has an "E-mount" attribute and a camera body has an "E-mount" attribute. It does not know those two facts mean the lens fits the body.
A product knowledge graph stores the connections, not just the values. Products, attributes, categories, brands, and use cases become nodes; the relationships between them — _fits_, _requires_, _replaces_, _pairs with_, _is a kind of_ — become the links. Once those links exist, the system can reason instead of just match.
Take a shopper who searches "camping gear for cold weather." A keyword search hunts for the literal words "cold weather" in your text and misses a sleeping bag rated to 15°F because nobody wrote "cold weather" in its description. A graph knows a 15°F rating _is_ cold-weather capable, that down insulation belongs to the same use case, and that someone buying that bag will probably want an insulated pad too — because the graph has seen how those nodes connect. That's the difference between a catalog that lists products and one that understands them. It's also what makes real semantic search possible: the system answers the question behind the words, not the words.
What This Actually Fixes
Concretely, three things get better, and they're the three that cost you money.
Search finds what you sell. When color families, materials, and use cases are standardized, the shopper looking for a red dress sees all forty-one, not nine. Fewer dead-end searches means fewer people assuming you're out of stock and leaving.
Returns drop. Most wrong-fit returns trace back to a fact that was on the page but unusable — the mount that didn't match, the voltage nobody flagged, the "water-resistant" watch that wasn't waterproof. Compatibility and context attributes catch those before the order ships, not after the angry email arrives.
Recommendations stop guessing. "Customers also bought" is popularity, not relevance. A graph can recommend the charger that actually fits the phone, the filter that fits the camera, the refill that fits the dispenser — because it knows the relationship, not just the co-purchase pattern. That's the gap between an upsell that annoys people and one that helps them.
Where to Start
You don't need to enrich a hundred thousand SKUs on day one. Start where the pain is loudest. Pull your top thirty search terms that return fewer than a handful of results and check whether the inventory exists under a different name — that tells you how much your search is hiding. Pull your highest-return SKUs and read the product page as if you were the customer who sent it back. Nine times out of ten the fact that would have stopped the return was missing, vague, or buried.
Fix those first. Standardize the attributes that drive your most-used filters, add compatibility to the categories where buyers get it wrong, and write the context lines that pre-empt your common returns. That alone moves numbers. The knowledge graph is what lets the improvement compound, because every new product slots into a structure that already knows how things relate.
This is the problem OrderHUB x RightPick is built to handle — enriching scattered catalog data into structured attributes and connecting them in a graph so the system can recommend the right products in the right quantities, with the reasoning to back it up. It's in early access right now, so we're not going to wave around customer numbers we haven't earned yet. But the approach is the one above, applied end to end rather than SKU by SKU.
The honest summary is this: your product pages were written to be read, one at a time, by people. The moment you want software to search, compare, recommend, or reason across the whole catalog, "written to be read" isn't enough. Enrichment turns the prose into facts. A graph turns the facts into understanding. And understanding is what turns a browsing session into a buying decision.